




Our Actionable Analytics squad has been working on a new feature to help coaches and scouts develop winning team strategies – learn all about how we are using a Regularized Adjusted Plus-Minus (RAPM) model with a Statistical Plus-Minus (SPM) Bayesian prior to estimate player impact stats.
A Regularized Adjusted Plus-Minus Model with a Statistical Plus-Minus Bayesian Prior!? Whew, I know you’re in a cold sweat flashing back to math class right now just reading that sentence. That’s OK. We’re going to break it down bit by bit.
But first, let’s start with the winning.
What’s the point?
Basketball scouts want to find winning players who they can bring into their programs and basketball coaches want to give more minutes to the winning players who are already on their teams. But basketball is a team sport – one where games are won or lost collectively, as a group – so how can we go about equitably assigning credit (or blame) to individuals for a team’s successes (or failures)? How do we identify who the winning players really are? That’s what we’re after with this stat.

Don’t we have enough stats already?
The box score is an imperfect solution to this bookkeeping challenge. We can tally up counts of points, rebounds, and assists – but we know they won’t capture the full picture. “It won’t show up in the box score,” goes the familiar broadcaster’s refrain, “but that was a game-changing play!” The spontaneous flare screen that frees up a three-point shooter, the perfectly-weighted hook pass that leads a short-rolling teammate into a 4-on-3 situation with a full head of steam, the well-timed cut that opens up space for somebody else’s drive… None of these little victories will be in the box score but they are all winning plays, nonetheless. Impact stats attempt to capture this “intangible” stuff.
What’s wrong with regular ole plus-minus?
The all-inclusive box score add-on called plus-minus, was a stat created to fill in the gaps left between the columns of the box score. A player with a positive plus-minus total is one whose team beat its opponent during the minutes while he was on the court during a particular game. Summing up plus-minus totals from multiple games gives a sense for whether a player has been part of a lot of successful units over the course of a season. The big drawback with using this “raw” version of plus-minus to spot winning players is a statistical bugaboo called “collinearity” or, what is more colloquially referred to as, “coattail riding”. The problem is that you can have a run-of-the-mill player who happens to play a lot of his minutes alongside All-Star teammates – and he will accumulate a high plus-minus total without necessarily making a huge contribution to his lineups’ success. Take Kyle Kuzma’s 2019-20 championship season with the Lakers, for example. He amassed an impressive +181 plus-minus total over the course of the regular season, landing him just outside the top 50 for that stat on the year and ranking him above the likes of Jalen Brunson, Joel Embiid, Shai Gilgeous-Alexander, and Devin Booker. But you may remember, some guys named LeBron James and Anthony Davis were also on that team and one or the other of those two (or both) were on the court with Kuzma 83% of the time that year. So how much credit did Kuzma deserve for the minutes the Lakers won when he was on the court? And how much could be chalked up to him playing alongside LeBron and AD?
That’s where the adjusted part of a Regularized Adjusted Plus-Minus model comes into play!
What does the “A” in RAPM stand for?
The adjustment begins with an accounting of all the players who were in the game with our player of interest (Kuzma, if you like) during all the possessions when he was on the court – his four teammates and his five individual opponents – using lineup data derived from play-by-play logs. The model tries to estimate what his plus-minus would be in a situation where – instead of playing with LeBron and AD – he was on the court alongside four average teammates and squaring off against five equally average opponents. The “A” in RAPM, then, stands for the player’s plus-minus total being adjusted for the quality of the teammates he played alongside and the opponents he played against. In the end, adjusted plus-minus is represented as a rate-based stat, as an estimate of the player’s individual contribution to his lineup’s margin of victory over 100 possessions.
Another thing we’re adjusting for is luck. Most coaches I know choose to believe that we make our own luck, that we’re the masters of our destiny. But there are definitely some things that are out of our control. We can’t control whether our opponents will make their free throws or miss them, and this shouldn’t really dictate a lineup’s net rating (or a player’s plus-minus). So, we account for opponent FT% in our plus-minus adjustments as well. Technically, this means that we’re producing a “luck-adjusted” RAPM – but that’s two words too many, in my opinion.
What does the “R” in RAPM stand for?
When you think about all the different 5-player offensive lineups that are used in an NBA season (thousands!) and all the different 5-player defensive lineups that they can face off against (also thousands!) you start to realize there are a LOT of possible combinations to evaluate. This creates what’s called a “sparse matrix” – as the model tries to figure out the different-sized effects each player has on all his teammates and opponents using only the small number of observations that are available to understand what happened in each situation. This combination – having lots of variables with a limited number of observations – makes the output from adjusted plus-minus models a little bit “noisy” for players who haven’t played many possessions. And this is even more of a challenge in collegiate basketball – where players have fewer opportunities to prove how good they are because there are fewer games in a season and less minutes in each game. Regularization is a way to deal with the noisy output that a sparse matrix like this can create for low-minute players. Regularization shrinks the estimates of a player’s adjusted plus-minus towards zero based on the number of possessions he’s played – low-minute players are pulled back aggressively to the mean level whereas high-minute players can convince the model that they are really impacting their lineups’ net ratings with their plus-minus stats. They can prove that they are winning players.
What does it mean that the model has a Bayesian prior?
OK – you’re half-way through! We covered the description of the Regularized Adjusted Plus-Minus (RAPM) model, now let’s dig into the Statistical Plus-Minus (SPM) Bayesian Prior – what does that mean exactly and why do we need one?
Even after all that regularizing and adjusting, plussing and minussing, RAPM output for an individual player can still bounce around quite a bit from year to year, suggesting that it’s not a perfectly stable measure of talent. A “prior” gives us a jumping off point for our plus-minus estimates, it represents “what we believe before seeing the evidence” as the Bayesians say. In this case, the “evidence” is a player’s adjusted plus-minus and the prior gives us a way to anchor his impact estimate to something more stable – his box score stats.
To come up with the prior for each player, we need to create another model, that uses box score stats as the inputs and the naïve RAPM estimates as the dependent variable to identify the typical relationships between box score stats and plus-minus stats. This is the so-called Statistical Plus-Minus (SPM) that helps to define the priors.
We can use the SPM and a player’s box score stats to find a prior estimate of the player’s impact and then we update that prior based on his regularized and adjusted plus-minus stats. If a player has played a lot of minutes, the “evidence” that he is helping or hurting his lineups – based on his adjusted plus-minus – will be credible and the RAPM estimate will make a large contribution to the overall estimate of his impact. If, on the other hand, a player hasn’t played many minutes, the RAPM evidence that he is helping or hurting his lineups will be weaker and the overall estimate of his impact will lean more on his box score stats.
What does the “S” in SPM stand for?
Stats!
Well, the “S” stands for “Statistical” I guess, technically, but yea, it’s stats! Basically. But which stats? Conventionally, the SPM prior would be informed by a player’s box score numbers – her points, rebounds, assists – measured in the form of per-100 stats. But this is Synergy, so the “box score” includes quite a bit more detail than it would in other places and that means we can include much more than the typical assortment of stats. Below is the list of metrics that we considered for inclusion as inputs in the SPM model.
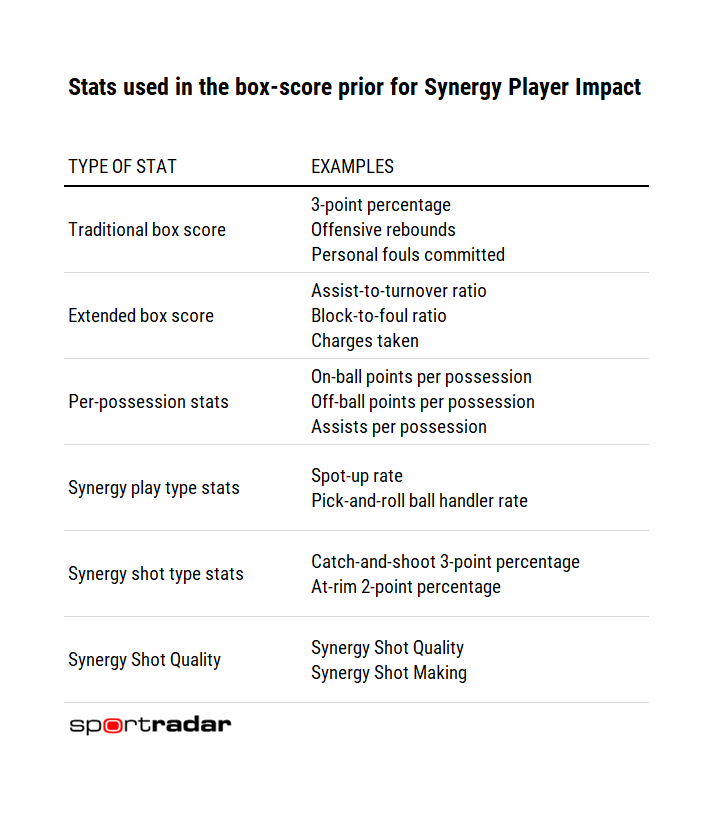
In the above table, many of the stats are rate-based and, for players who haven’t played many minutes, rate-based stats can be unreliable. For example, imagine a player who has made six field goals on ten attempts. He’d have a FG% of 60, but would you consider him to be a better shooter than a player who has made five hundred field goals on one thousand attempts (and whose FG% is “only” 50)? Think about it – if the player with 6 FGM was really a great shooter he’d probably be taking a lot more shots! To account for this issue, we stabilize FG% (and the other box-score stats being used in the SPM) by padding them with a certain number of makes and attempts. Appropriate padding numbers are set separately for each league and level.
We are using what’s called “elastic net” regression to figure out which of these many stats from Synergy’s expanded box score tend to be the best predictors of adjusted plus-minus. Elastic net is another form of regularization (flip back to “chapter 5: what does the R in RAPM stand for” to read more) that can be implemented in one of two ways, as ridge or lasso. The lasso flavor of regularization attempts to “zero-out” the influence of uninformative stats that don’t do a good job of predicting RAPM, it’s a variable selection technique – some stats go in the model, and some are kept out. Whereas, instead of excluding specific box score stats from the model entirely, ridge regression just reduces the influence of the least informative stats, leaving the best predictors of RAPM to do the heavy lifting among an ensemble of stats that all contribute at least a little bit to the algorithm. In practice, we find that ridge regression wins out over lasso in cross validation in this particular context – when we test the model output on new data that wasn’t used to train the model – so we end up including all of the above stats in the SPM model. Still, some stats contribute more than others to the prior estimate of each player’s impact and the effect sizes (ie. the weights applied to each stat in the SPM algorithm) are calculated separately for every league and level we cover.
The key point to remember is that the SPM is optimized to maximize predictive power using cross validation, so the weights that are applied to each stat are derived systematically in a way that provides the best prior estimate of RAPM with all the available box score stats. And, again, the prior estimate produced by the SPM becomes just a point of departure for the actual evidence of a player’s impact provided by his adjusted plus-minus numbers.
What does the output look like?
In the end, taking into account each player’s box-score prior along with his RAPM – that is, his plus-minus total having been adjusted for the quality of the players he’s shared the court with as a teammate or opponent – we are left with an estimate of the player’s impact on his team on offense, on defense, and overall. These stats are represented on a points-per-100-possession scale relative to an average player.
Start by imagining a game full of completely average players – five average players on offense and five average players on defense – being played with 100 possessions for each team. For simplicity, let’s pretend the score of that game tends to be 100 – 100 at the end. If a player has an offensive impact of +5 points per 100 possessions, the expectation would be that subbing her into this game would make her team 5 points better on offense, changing the score to 105 – 100. If a player has a defensive impact of +5 points per 100 possessions, the expectation would be that subbing her into this game would make her team 5 points better on defense, changing the score to 100 – 95. If the same player had an offensive impact of +5 points per 100 possessions and a defensive impact of +5 points per 100 possessions her net impact – what we are calling Synergy Player Impact or SPI for short – would be +10 points per 100 possessions and the expectation would be that subbing her into this game would make her team 10 points better and change the score to 105 – 95.
So that’s three metrics – offensive impact, defensive impact, and Synergy Player Impact (or net impact) – and from there we add one more called Wins Added which is a function of net impact and playing time. We take Synergy Player Impact (net points above an average player per 100 possessions on the court) and we multiply it by the total number of possessions the player spent on the court to estimate the total number of points the player added this season relative to an average player. Finally, we convert points added to wins added by dividing by the average number of points it takes to win a game in the league the player is in.
How long does it take for a player’s impact to become apparent?
Plus-minus stats from a single game are notoriously unreliable. So how many possessions do we need to observe before a plus-minus stat or RAPM tells us something useful?
In truth, we need to see at least hundreds of on-court possessions for a player before his RAPM begins to push the estimate of his impact away from his box-score prior. To help us get to that number faster, we’re using information from a player’s previous seasons, but we apply an exponential weighting to games based on recency. This way, information from previous seasons can help stabilize our impact estimates, but recent games influence the estimates much more than games from the distant past. A player’s stats from games he’s played in other leagues don’t influence his impact estimate at all.
What did we leave out of Synergy Player Impact?
The box-score priors incorporate lots of information that wouldn’t be available outside of Synergy but there are also some pieces of information that we left out because we want to be able to produce impact stats for as many leagues and levels as possible. For example, the priors do not include height (which is something we don’t have a complete accounting of for the hundreds of thousands of players in the Synergy database). Likewise, the prior does not incorporate position or offensive role nor do they include recruiting ranks or draft position. Some other RAPM models include this information as part of their priors.
What situations can fool Synergy Player Impact?
Like we talked about before – RAPM is meant to adjust for “collinearity” but there are specific situations where the model struggles to do its job. For example, when a coach uses “platoon lineups” that substitute players 5 at a time, or more generally, when teammates share the court (and the bench) very frequently, it makes it hard for the model to separate the contributions of the individual players.
So how much credit did Kuzma deserve, actually?
How much credit did Kuzma deserve for the minutes the Lakers won when he was on the court during the 2019-20 regular season? And how much credit should be attributed to him playing alongside LeBron and AD that year? SPI can help us sort it out!
Looking back at the historic net impact stats for that season, we have LeBron listed at +6.8 points per 100 possessions, which was the highest SPI in the league. And his fellow first-team All-NBA teammate AD? We had him at no. 12 in the NBA, with SPI of +4.1. Kuzma – who, remember, was around 50th in raw plus-minus – clocked in outside the top 200 for SPI. We rated Kuzma as a player who was basically average, -0.4 points per 100 possessions.
We think our new player impact stats will help coaches and scouts find winning players. These new metrics will be helpful for self evaluation, opponent scouting, and recruiting – especially in the transfer portal. Player impact stats will be estimated for many of the leagues and levels covered by Synergy.
The development of the Synergy Player Impact metric was led by JP van Paridon. JP is building tools to help coaches, scouts, and players find winning team strategies as part of Synergy’s Actionable Analytics Team.







